Chào các bạn, nay lại đến chu kỳ lười biếng của mình rồi (với thật ra thì dạo trước cày kha khá rồi nên nội dung còn lại cũng không nhiều), nên mình sẽ chuyển sang viết khoảng 1-2 bài/tuần tuỳ cảm hứng. Với tuần rồi mình cũng có được idol ✨🌙 của mình giới thiệu cuốn sách Tìm mình trong thế giới hậu tuổi thơ, cũng khá hay, nếu hứng thú các bạn có thể tìm đọc. Còn giờ thì mời bạn thưởng thức Newsletter #51.
p-fast trie: lexically ordered hash map
Tác giả Tony Finch giới thiệu một cấu trúc dữ liệu thử nghiệm mới gọi là “p-fast trie”, được thiết kế như một lựa chọn thay thế tiềm năng cho qp-trie. Đây là một kiểu hash map có thứ tự theo từ điển, mang đến những ưu điểm thú vị trong việc tìm kiếm và truy xuất dữ liệu.
Cấu trúc p-fast trie sử dụng hash map được tổ chức thành nhiều tầng, mỗi tầng tương ứng với một tiền tố của khóa. Các đối tượng lá tạo thành danh sách liên kết vòng, và sử dụng bitmap cùng mảng nén popcount để điều hướng hiệu quả. Điểm đặc biệt của thiết kế này là khả năng tìm kiếm chính xác với độ phức tạp O(1), trong khi tìm kiếm phần tử trước/sau có độ phức tạp O(log k), với k là độ dài khóa.
Mặc dù p-fast trie có những ưu điểm như tìm kiếm chính xác nhanh và tìm kiếm phần tử trước/sau đơn giản hơn so với qp-trie, nhưng cũng tồn tại những hạn chế về việc sử dụng bộ nhớ cao hơn và khả năng cache-friendly kém hơn. Tác giả thẳng thắn thừa nhận đây chỉ là một khái niệm thử nghiệm và vẫn chưa rõ hiệu quả thực tế của nó, đồng thời mời gọi cộng đồng nghiên cứu và phản hồi thêm.
Bài viết này rất phù hợp cho những ai quan tâm đến các cấu trúc dữ liệu tiên tiến và muốn hiểu sâu hơn về các phương pháp tối ưu hóa trong lĩnh vực khoa học máy tính.
Big O vs Hardware: Better Complexity ≠ Better Performance
Bài viết này khám phá một khái niệm quan trọng mà nhiều lập trình viên thường bỏ qua: độ phức tạp thuật toán tốt hơn không luôn đồng nghĩa với hiệu suất thực tế tốt hơn. Tác giả minh họa điều này thông qua việc phân tích chi tiết ba thuật toán tìm ước số chung lớn nhất (GCD) khác nhau.
Hiệu suất thực tế phụ thuộc vào hai yếu tố phần cứng chính: số lượng lệnh và số lệnh thực hiện trên mỗi chu kỳ (IPC). Bài viết so sánh thuật toán Euclid dựa trên phép trừ với độ phức tạp O(max(a,b)), thuật toán Euclid dựa trên phép chia dư với O(log(max(a,b))), và thuật toán nhị phân Stein được tối ưu hóa cho phần cứng.
Điểm mấu chốt của bài viết là “Định luật Sắt về hiệu suất”: hiệu suất thực tế không chỉ phụ thuộc vào độ phức tạp lý thuyết mà còn phụ thuộc vào cách mã nguồn tương tác với đặc tính phần cứng cụ thể. Số lượng lệnh ít hơn không đảm bảo thực thi nhanh hơn, và các thuật toán thân thiện với phần cứng có thể vượt trội hơn những thuật toán hiệu quả hơn về mặt lý thuyết.
Bài viết khuyến nghị các lập trình viên nên xem xét đặc tính phần cứng khi thiết kế thuật toán, đo đạc hiệu suất với các kích thước đầu vào khác nhau, và tối ưu hóa cho cả độ phức tạp lý thuyết lẫn hiệu quả phần cứng.
Claude Code Is All You Need
Bài viết này giới thiệu về Claude Code - một công cụ lập trình và phát triển ứng dụng được hỗ trợ bởi các mô hình AI Claude của Anthropic. Tác giả khám phá khái niệm “vibe coding” - việc tạo ra phần mềm thông qua các tương tác hội thoại với AI, cho thấy Claude Code có khả năng tạo ra các ứng dụng hoàn chỉnh chỉ với đầu vào tối thiểu từ con người.
Claude Code thể hiện khả năng ấn tượng trong việc xây dựng các ứng dụng CRUD hoàn chỉnh chỉ với một câu lệnh, thiết lập hạ tầng sản xuất, di chuyển các dự án hiện có, và thực hiện các tác vụ quản trị. Tác giả đã thử nghiệm với nhiều dự án thực tế như SmartSplit (bản sao SplitWise), trình xây dựng startup tự động, plugin xếp hạng bình luận HackerNews, và ứng dụng xử lý sao kê ngân hàng.
Để đạt được kết quả tốt nhất với Claude Code, tác giả khuyến nghị cung cấp đầu vào chi tiết và ngữ cảnh phong phú, sẵn sàng lặp lại và hướng dẫn AI, duy trì sự giám sát của con người đặc biệt với các hệ thống quan trọng, và hiểu rõ khả năng cũng như hạn chế của AI.
Mặc dù Claude Code đặc biệt mạnh trong PHP và các ứng dụng web đơn giản, rất hữu ích cho việc tạo nguyên mẫu nhanh và khởi tạo dự án, nhưng tác giả nhấn mạnh rằng công cụ này không hoàn hảo và vẫn cần sự hướng dẫn cẩn thận từ con người.
HTTP is not simple
Daniel Stenberg, tác giả của curl, thách thức quan niệm phổ biến rằng HTTP là một giao thức đơn giản. Ông lập luận rằng HTTP thực tế phức tạp hơn nhiều so với những gì mọi người thường nghĩ, đặc biệt khi xem xét việc triển khai một client HTTP tuân thủ đầy đủ các tiêu chuẩn.
Những phức tạp cụ thể bao gồm xử lý xuống dòng với độ dài dòng tùy ý và các tiêu chuẩn kết thúc dòng không nhất quán (CR, LF, hoặc cả hai), trong khi các header dựa trên octet chứ không phải UTF-8. Việc phân tích cú pháp cũng gặp nhiều thách thức như nhiều cách khác nhau để xác định kết thúc nội dung, việc phân tích số khó khăn, các quy tắc phức tạp về khoảng trắng và token, cũng như các kỹ thuật “folding” header.
HTTP đã tích lũy độ phức tạp qua nhiều thập kỷ với hơn 40 tài liệu RFC riêng biệt, sự gia tăng đáng kể về quy mô đặc tả theo thời gian, và các hành vi không nhất quán của phương thức và header. Các trình duyệt thường ưu tiên trải nghiệm người dùng hơn là tuân thủ nghiêm ngặt các tiêu chuẩn.
Tác giả gợi ý rằng độ phức tạp này có thể là đặc tính cố hữu của các giao thức thành công và tồn tại lâu dài, khi những gì bắt đầu đơn giản thường trở nên phức tạp thông qua việc thích ứng và mở rộng liên tục.
Building a web search engine from scratch in two months with 3 billion neural embeddings
Wilson Lin chia sẻ hành trình xây dựng một công cụ tìm kiếm web tùy chỉnh sử dụng mô hình nhúng thần kinh trong vòng hai tháng. Dự án này tập trung vào việc cải thiện chất lượng và độ liên quan của kết quả tìm kiếm thông qua việc hiểu ý định truy vấn thay vì chỉ khớp từ khóa đơn thuần.
Về mặt kỹ thuật, tác giả đã sử dụng 200 GPU để tạo ra 3 tỷ mô hình nhúng thần kinh, phát triển một crawler có thể xử lý 50.000 trang mỗi giây, và xây dựng hệ thống phân tán sử dụng RocksDB cho lưu trữ, HNSW được phân đoạn cho tìm kiếm vector, với 4 TB RAM và 82 TB SSD. Hệ thống đạt được độ trễ truy vấn đầu cuối khoảng 500ms.
Các đổi mới chính bao gồm việc sử dụng kỹ thuật phân đoạn ngữ nghĩa và bảo tồn ngữ cảnh, triển khai chuẩn hóa nội dung trang web tiên tiến, và phát triển phương pháp móc nối câu lệnh để bảo tồn ngữ cảnh ngữ nghĩa. Dự án cho thấy mô hình nhúng thần kinh cung cấp khả năng hiểu tìm kiếm vượt trội, nhưng chất lượng tìm kiếm phụ thuộc nhiều hơn vào crawling và lọc hơn là công nghệ.
Tác giả khuyến nghị khám phá các chỉ mục tìm kiếm mã nguồn mở được cộng đồng duy trì, nghiên cứu mô hình nhúng tĩnh và các mô hình nhúng hiệu quả hơn, tận dụng hạ tầng crawling hiện có, và tập trung vào nội dung chất lượng thay vì số lượng.
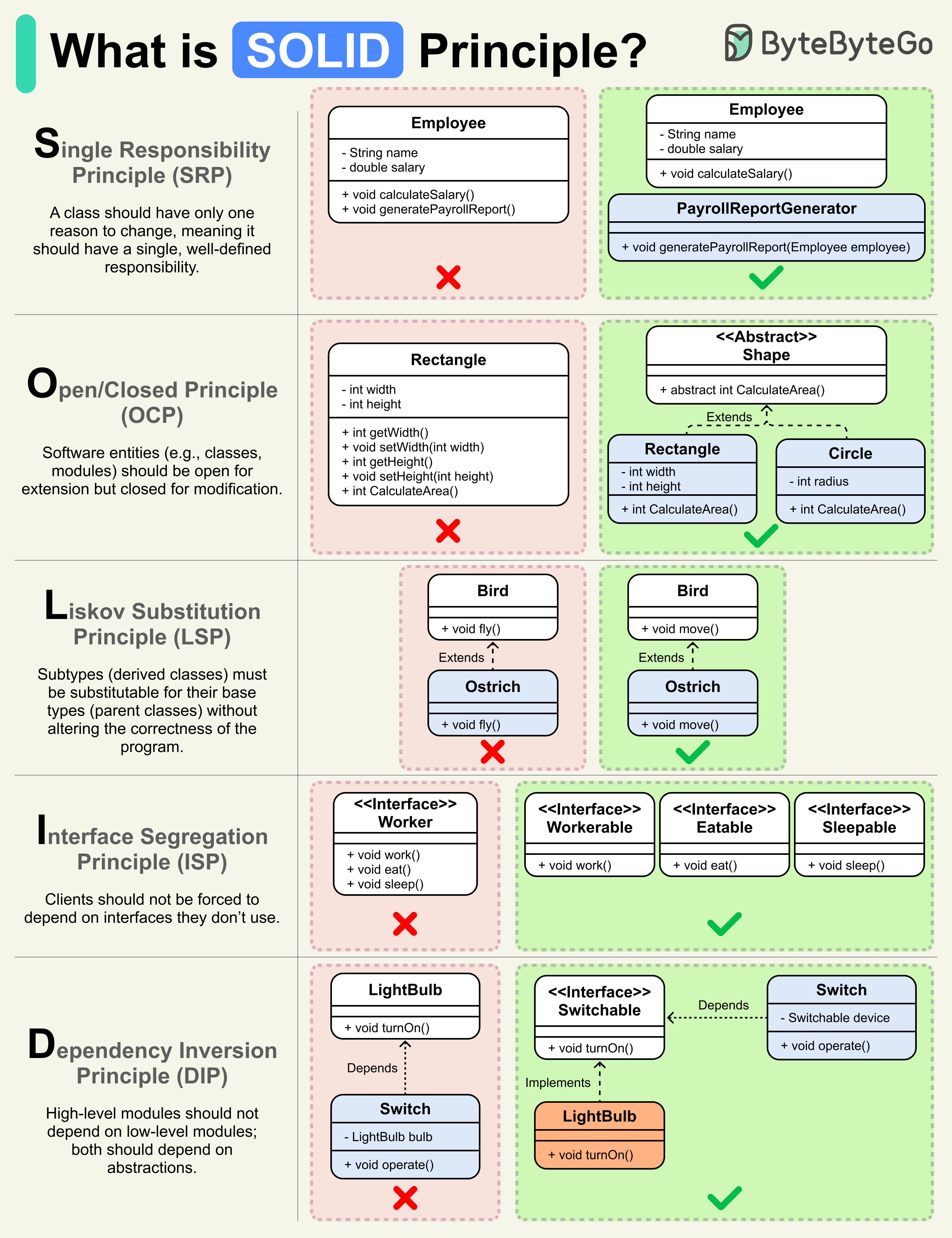
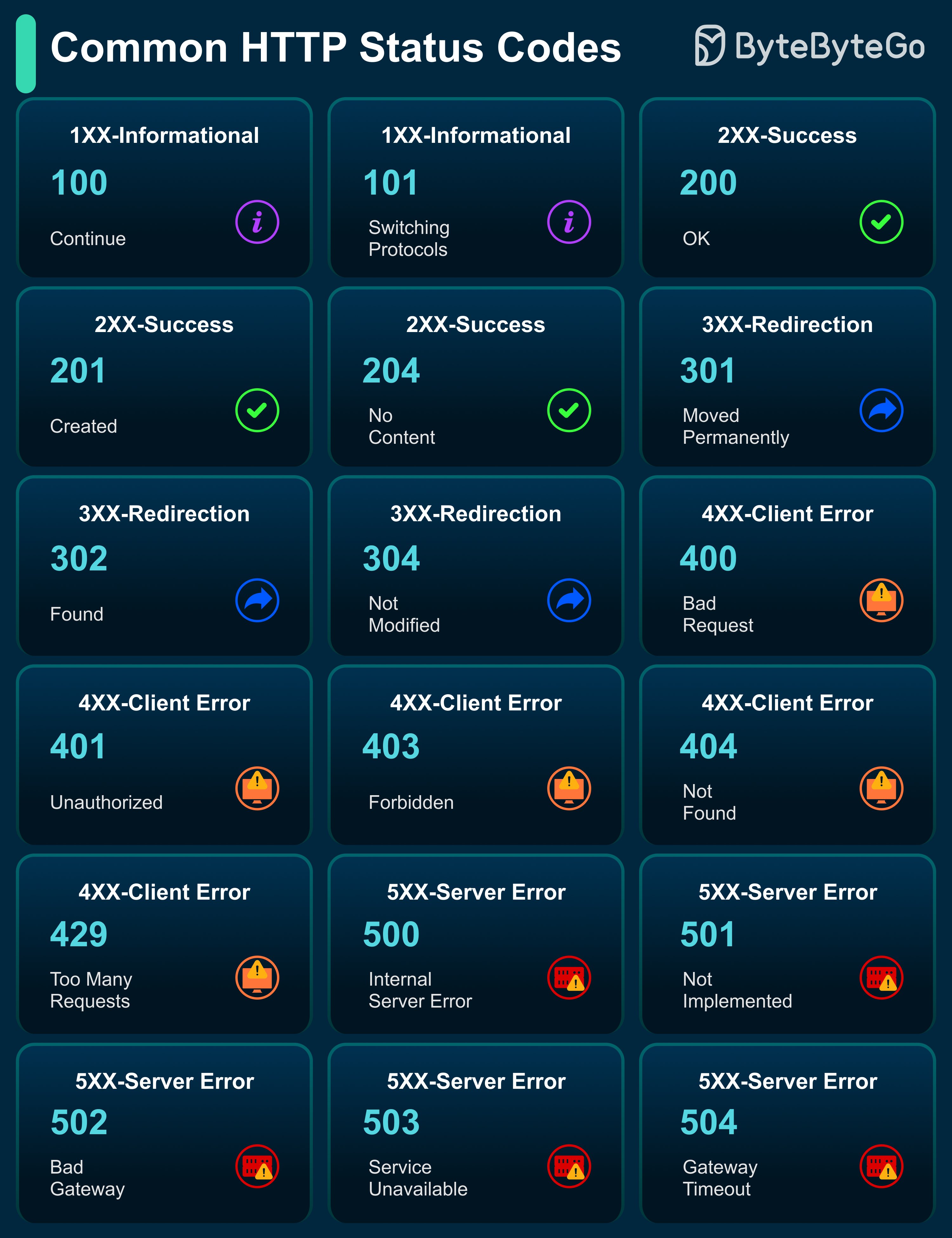
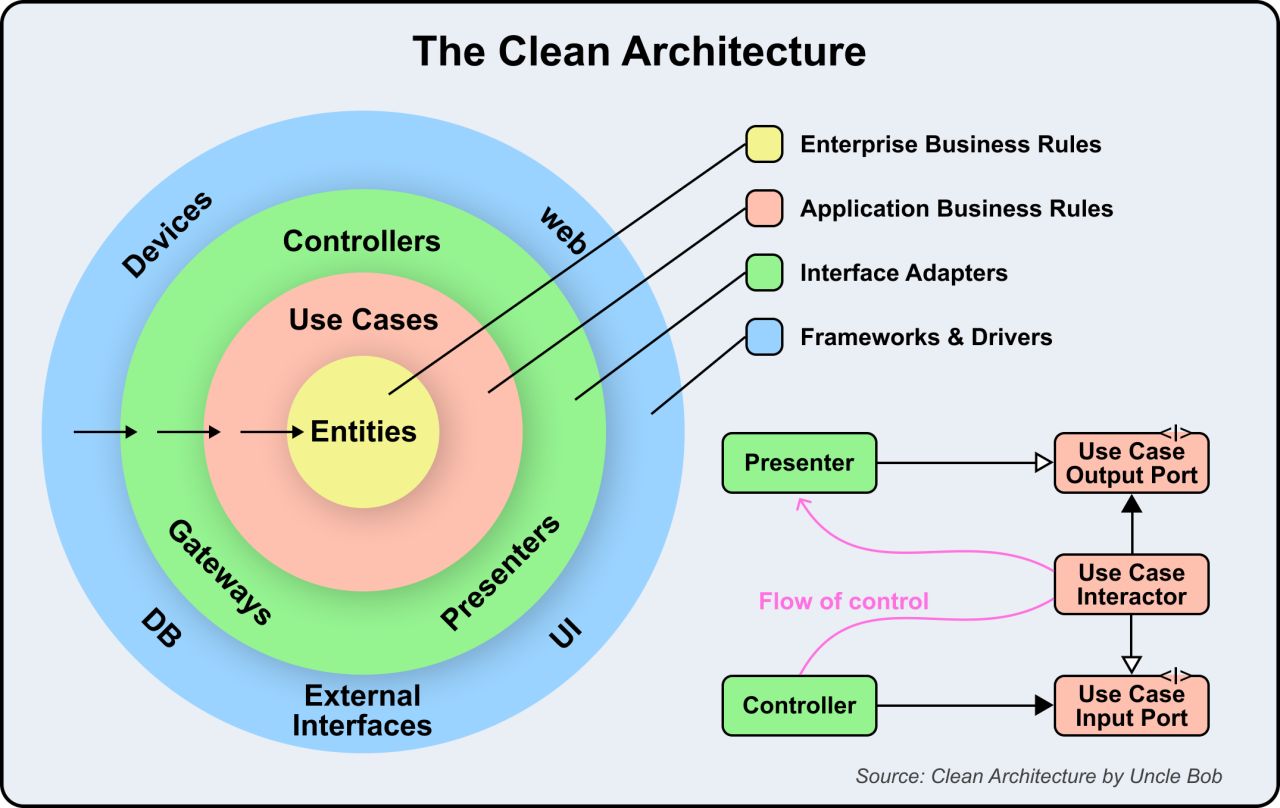
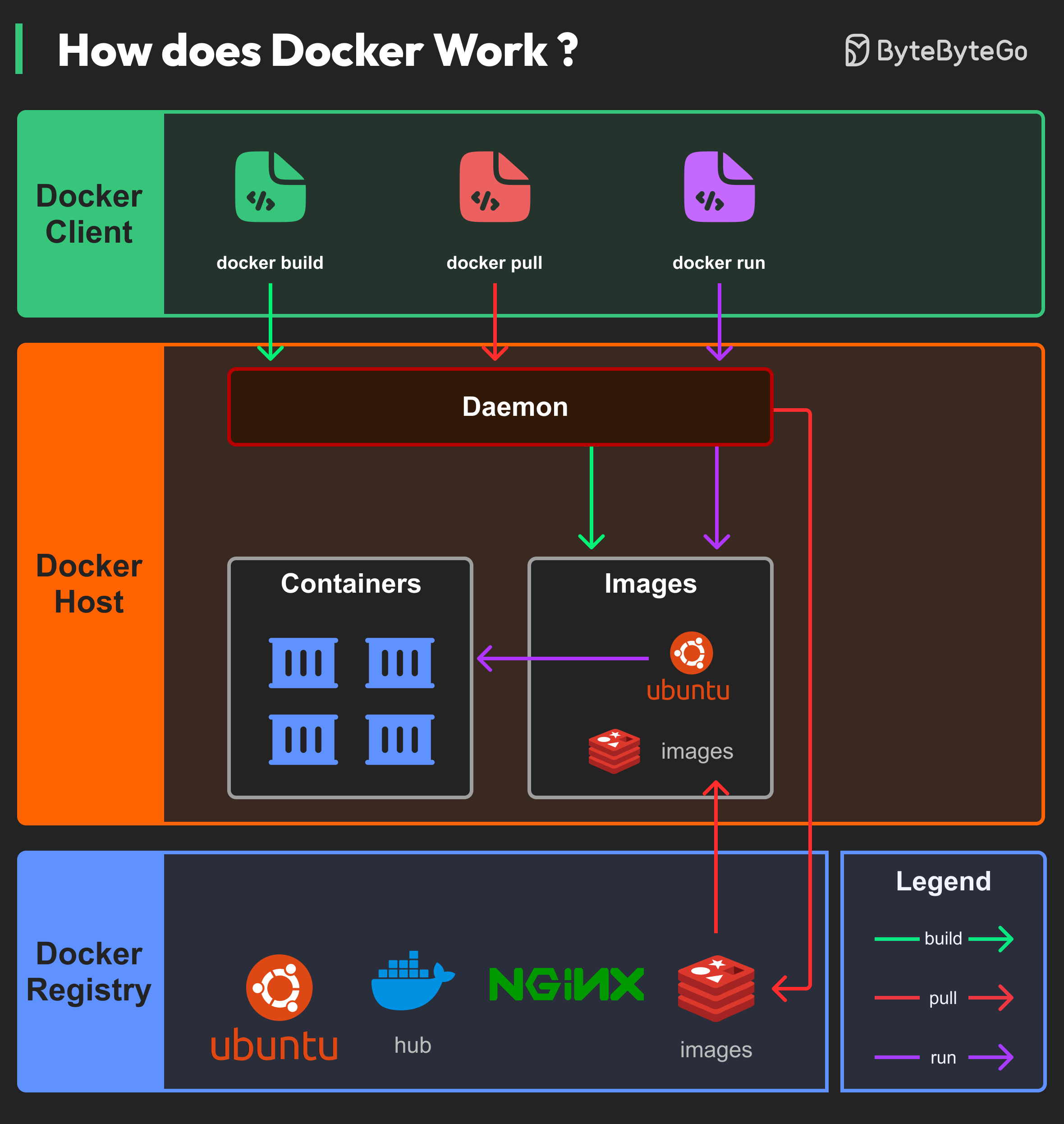
Bonus: Vài ảnh hay ho đến từ ByteByteGo